
하둡(Hadoop)
Open Source Java Software Framework
Google의 GFS(Google File System) 논문을 기반으로 출발함.
2006년 더그 커팅과 마이크 캐퍼 렐라가 개발함.
하둡 분산 파일 시스템(HDFS : Hadoop Distrubuted File System)
하둡의 분산형 파일 시스템
Name Node : 파일의 메타(meta) 정보를 관리
Data Node : 실제 데이터를 저장하고 내보내는 역할

맵리듀스(MapReduce)
Map Reduce라는 두 개의 합수의 조합
분산/병렬 시스템에서 데이터를 처리하는 프레임 워크
Map : 나누어진 단위에서 계산
Reduce : Key 별로 합침

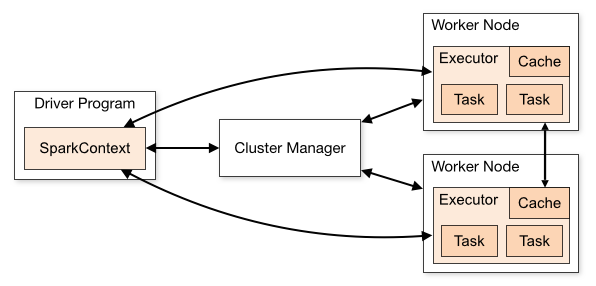
스파크(Spark)
In-Memory 기반 Open Source Cluster Computing Framework
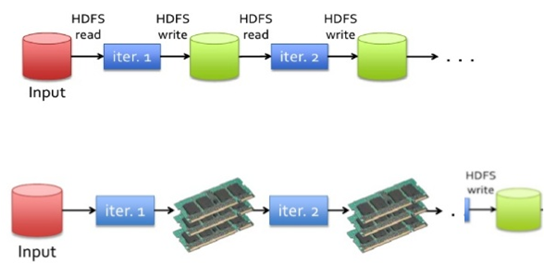
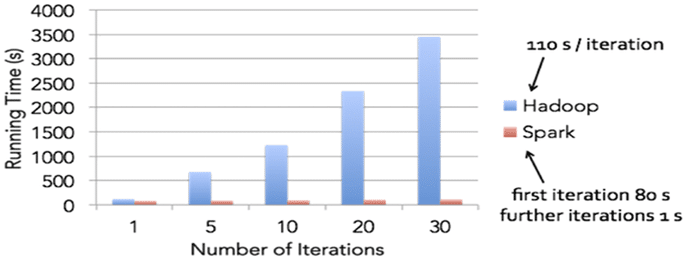
Hadoop의 MapReduce와 유사한 역할을 하지만 Memory 활용을 극대화했기 때문에 연산 속도가 월등히 빠름
최근에서 Memory 가격이 많이 저렴해졌고 H/W 성능도 많이 올라가서 MapReduce 보다 Spark를 선호
Scala, Python 으로 개발 가능
스파크 핵심 개념 RDD(Resilient Distributed Datasets)
스파크에서 활용되는 내부 데이터 모델
병열 처리가 가능하고 장애가 발생할 경우에서 스스로 복구될 수 있는 내성을 가지고 있음.
RDD는 한번 생성되면 바뀌지 않으며 다른 형태로 변환이 필요할 경우 새로운 RDD를 만들어 냄
장애 시에는 RDD 진행 절차를 기억했다가 그대로 수행하여 빠르게 복구함.
Spark SQL - SQL을 사용해 데이터를 처리
Spark Streaming - 실시간 스트리밍 데이터를 처리하는 프레임워크
Spark Mllib - 머신러닝 알고리즘 라이브러리
Spark GraphX - 그래프 연산용 서브 모듈
Hadoop VS Spark
| 구분 | Hadoop | Spark |
| License | Open Sourec,Apache | Open Sourec,Apache |
| Processing Model | On-disk, Batch | In-Memory, On-Disk, Batch, Streaming(Near Real-Time) |
| Language Written | JAVA | Scala |
'데이터분석 > 기초' 카테고리의 다른 글
| [데이터분석] 데이터 분석의 꽃 통계 1 (2) | 2021.12.15 |
|---|---|
| [데이터분석] Data Engineering(엔지니어링) 6 (0) | 2021.12.14 |
| [데이터분석] Data Engineering(엔지니어링) 4 (0) | 2021.12.12 |
| [데이터분석] Data Engineering(엔지니어링) 3 (2) | 2021.12.11 |
| [데이터분석] Data Engineering(엔지니어링) 2 (2) | 2021.12.10 |








최근댓글